Yapay Sinir Ağları Nedir ?
İnsan beynindeki sinir hücrelerinden esinlenerek geliştirilen yapay sinir ağları, günümüzde görüntü tanıma, doğal dil işleme ve oyun yapay zekası gibi birçok alanda kullanılmaktadır. Peki, bu sistemler nasıl öğrenir ve çalışır?
Nöronlar (Neurons)
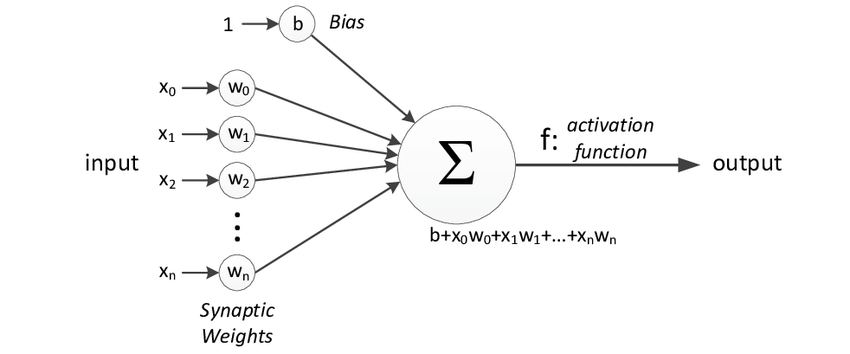
Yapay sinir ağlarının temel yapı birimi olan nöronlar, bir katsayı (weight) ve bir ağırlığa (bias) sahip olan bir fonksiyona benzerler. Ancak, bir fonksiyondan farklı olarak birden fazla girdiye sahip olabilirler ve her girdi için farklı katsayılara sahip olabilirler. Ayrıca, bünyelerinde bir aktivasyon fonksiyonu bulunur. Aktivasyon fonksiyonunun ne olduğundan ileride bahsedeceğiz. Bir nöronun görselleştirilmiş matematiksel karşılığı:
Aktivasyon Fonksiyonları
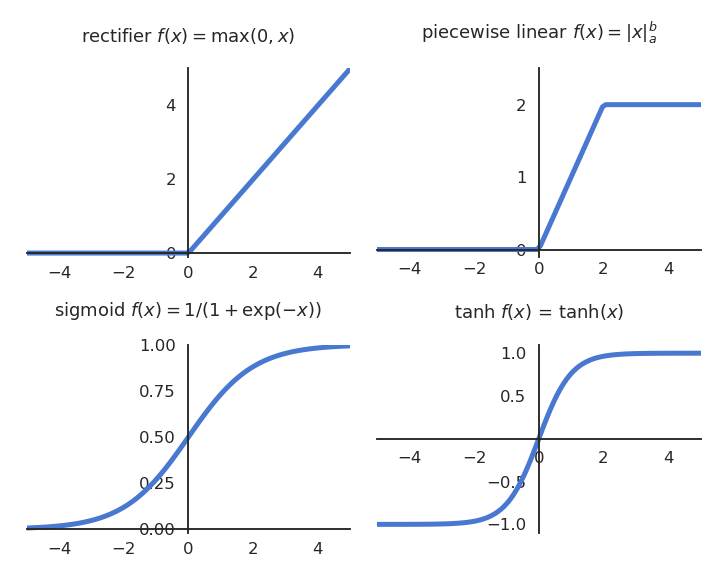
Yapay sinir ağlarında, aktivasyon fonksiyonları nöronların çıkışlarını belirleyen matematiksel fonksiyonlardır. Aktivasyon fonksiyonları, girdiyi alıp belirli bir dönüşüm uygulayarak ağırlıklı toplamın sonucunu sınırlar. En yaygın aktivasyon fonksiyonları şunlardır:
Sigmoid Fonksiyonu
Sigmoid fonksiyonu, çıkışları aralığında sınırlandıran doğrultulmuş bir fonksiyondur. Matematiksel ifadesi şu şekildedir:
Bu fonksiyon, özellikle lojistik regresyon ve eski sinir ağı modellerinde yaygın olarak kullanılmıştır. Ancak, türevlerinin küçük olması sebebiyle gradyan kaybolma problemi yaratabilir.
Tanjant Hiperbolik (Tanh) Fonksiyonu
Tanh fonksiyonu, sigmoid fonksiyonuna benzerdir ancak çıktıları aralığındadır. Matematiksel olarak şu şekilde tanımlanır:
Bu fonksiyon, sıfır merkezli olması nedeniyle genellikle sigmoid fonksiyonuna göre daha avantajlıdır.
ReLU (Rectified Linear Unit) Fonksiyonu
ReLU fonksiyonu, modern sinir ağlarında en yaygın kullanılan aktivasyon fonksiyonlarından biridir ve şu şekilde tanımlanır:
ReLU, gradyan kaybolma problemini büyük ölçüde azaltır ve hesaplama açısından daha verimlidir. Ancak, negatif girdilerde gradyanın sıfır olması nedeniyle "ölü nöron" problemi ortaya çıkabilir.
Leaky ReLU Fonksiyonu
Leaky ReLU, ReLU fonksiyonunun sıfır olmayan küçük negatif bir eğim ile değiştirilmiş versiyonudur:
Burada genellikle küçük bir sabit değer olarak (örneğin ) seçilir. Bu sayede, negatif girdiler için de küçük bir gradyan korunur.
Softmax Fonksiyonu
Softmax fonksiyonu, özellikle sınıflandırma problemlerinde çıktı katmanında kullanılır. Birden fazla sınıf için olasılık dağılımı sağlar ve şu şekilde tanımlanır:
Bu fonksiyon, girdileri normalize ederek olasılık değerlerine dönüştürür ve toplamlarını 1 yapar.
Layerlar (katmanlar)
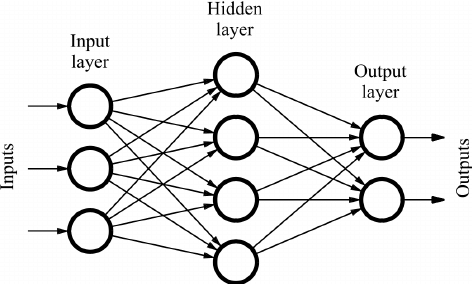
İhtiyacımız olan temel bileşenlerin neler olduğunu öğrendik. Peki bu bileşenleri nasıl birleştireceğiz ve elde edeceğimiz şey neye benzeyecek? Bu soruları cevaplamak için ilk olarak layer kavramının ne olduğundan bahsetmeliyiz.
layerler içim üst üste gelmiş noronlar desek çokta sorun olmaz aynı alanda parelel olarak çalışan noron toplulukları denebilir kendileri için bir araya gerelerk neurol networkları oluşturular.katmanlar bulundukları yere göre üçe ayrılırlar:
- Giriş Katmanı (Input Layer): Giriş katmanı, verilerin ham bir şekilde girdigi ilk katmandır. Bu katmandadır.buyuklugu veri setine göre değişir örnek 28 x 28 bir görsel için her piksel için bir noron atanır.
- Gizli Katmanlar (Hidden Layers): Gizli katmanlar, modelin öğrenmesini sağlayan katmanlardır. Bu katmanlarda, nöronlar çeşitli ağırlıklar ve aktivasyon fonksiyonları kullanarak veriyi işler. Katmanlar arasında yapılan işlemler, verinin daha soyut ve anlamlı hale gelmesini sağlar. Ne kadar fazla gizli katman varsa, ağ o kadar derinleşir.
- Çıktı Katmanı (Output Layer): Çıktı katmanı, modelin nihai tahminini yaptığı katmandır. Bu katman, ağın amacına göre değişir. Örneğin, sınıflandırma problemlerinde her bir sınıf için bir nöron bulunabilir ve bu nöronların çıktıları, modelin tahmin ettiği olasılıkları temsil eder.
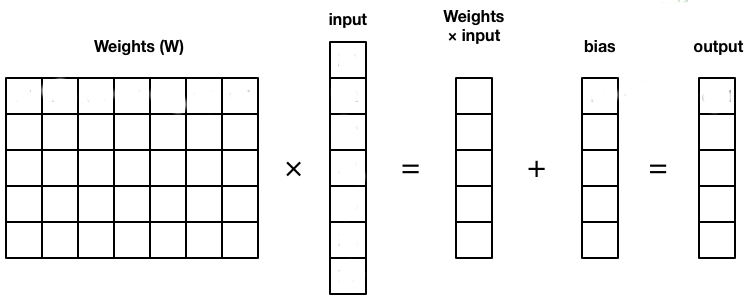
Katman Hesaplamalarına Genel Bakış
"Katmanların ne olduğunu öğrendik. Şimdi bunu bilgisayarlara anlatırken, ağırlıkları matrisler halinde tutup, gelen input ile matris çarpımı yaparak bir sonraki katmana geçecek verileri elde edebiliyoruz. Bu matris, gelen input ile nöron sayısı kadar genişliğe sahip oluyor. Biasları da aynı şekilde bir matriste tutup gerekli matris toplaması ile sonraki katmana verilmesi gereken veri elde edebiliriz.Bu matrislerin transpozları kullanrak modele ters taraftan bakılabilir.Egitim sürecinde bu bakışın sebebini ele alacagız.
Tabii, sana yapay sinir ağlarının eğitimi konusunu bu başlıklar altında temel ve anlaşılır şekilde anlatayım:
Yapay Sinir Ağlarının Eğitimi
Bir yapay sinir ağı; katmanlar, nöronlar, ağırlıklar ve aktivasyon fonksiyonlarından oluşur. Ancak ağı oluşturmak yetmez — bu ağı belirli bir problemi çözmesi için eğitmemiz gerekir. Bu süreçte iki önemli temel kavram vardır:
Loss Fonksiyonu (Kayıp Fonksiyonu)
-
Loss fonksiyonu (ya da cost function), ağın tahmin ettiği sonuç ile gerçek (beklenen) sonuç arasındaki farkı sayısal olarak ifade eder.
-
Yani, “ağ ne kadar hata yapıyor?” sorusuna cevap verir.
-
Örneğin:
-
Regresyonda genellikle Mean Squared Error (MSE) kullanılır:
-
Sınıflandırmada genellikle Cross Entropy Loss kullanılır.
-
- Eğitim boyunca hedefimiz bu loss fonksiyonunu minimuma indirmektir.
Optimizasyon
-
Optimizasyon, loss fonksiyonunu minimize edecek şekilde ağın ağırlıklarını güncelleme sürecidir.
-
En çok kullanılan algoritma Gradient Descent (Gradyan İnişi):
-
Loss fonksiyonunun ağırlıklar (parametreler) üzerindeki türevini (gradyanını) hesaplar.
-
Bu türev, loss’un nasıl değiştiğini gösterir.
-
Ağırlıkları bu gradyanın ters yönünde güncelleriz ki loss azalsın:
burada
- $\eta$: learning rate (öğrenme oranı)
-
-
Daha gelişmiş optimizer’lar:
- Momentum, RMSProp, Adam gibi algoritmalar bu güncellemeyi daha hızlı ve stabil hale getirir.
Backpropagation (Geri Yayılım) Nedir?
Backpropagation (geri yayılım), yapay sinir ağlarını eğitmek için kullanılan temel algoritmadır.
Ağ çıktısı ile gerçek değer arasındaki hatayı hesapladıktan sonra bu hatanın ağın ağırlıklarını nasıl değiştirmesi gerektiğini belirler.
Nasıl Çalışır?
Backpropagation iki temel aşamadan oluşur:
İleri Yayılım (Forward Pass)
- Girdiler ağdan geçirilir ve her katmandaki ağırlıklar ile aktivasyon fonksiyonları yardımıyla çıktıya ulaşılır.
- Bu sayede tahmin edilen bulunur.
Geri Yayılım (Backward Pass)
- Çıktıda hesaplanan loss (kayıp) değerine bakarak her katmandaki ağırlıkların bu hataya katkısını bulur.
- Zincir kuralı (chain rule) kullanılarak loss’un ağırlıklara göre türevleri hesaplanır.
- Böylece her ağırlığın ne kadar değiştirilmesi gerektiği (gradyan) ortaya çıkar.
Matematiksel Özet
Örnek bir ağda bir ağırlık için güncelleme şu şekilde olur:
- Loss fonksiyonunun türevi (gradyan) bulunur:
- Bu türev, learning rate ile çarpılır ve ağırlık güncellenir:
bu konudaki iyi bir açıklama için 3blue1brown calculus videolarına bakılabilir.
Sinir aglarının Python ile inşa edlimesi
ögrenmememiz gereken kavramları ögrendik şimdi bunu kodlama ile prtaige dökme zamanı burda mnist adlı el ile yazılmış sayıların oldugu popoüler bir veri setini kullanacagım.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ---------------------- VERİ YÜKLEME ----------------------
testdata_pd = pd.read_csv('data/mnist_test.csv')
traindata_pd = pd.read_csv('data/mnist_train.csv')
traindata = traindata_pd.to_numpy(dtype=np.uint8)
testdata = testdata_pd.to_numpy(dtype=np.uint8)
testdata = testdata / 255.0
traindata = traindata / 255.0
# ---------------------- AKTİVASYONLAR ----------------------
def relu(x):
return np.maximum(0, x)
def relu_derivative(z):
return z > 0
def softmax(x):
exp = np.exp(x - np.max(x))
return exp / np.sum(exp, axis=0)
# ---------------------- ARAÇ FONKSİYONLAR ----------------------
def one_hot(y, num_classes=10):
vec = np.zeros((num_classes, 1))
vec[y] = 1
return vec
def random_value(data):
x = np.random.randint(0, data.shape[0])
return data[x, :]
def show_image(data, predicted=None):
label = int(data[0] * 255)
img = data[1:].reshape(28, 28)
plt.imshow(img, cmap='gray')
title = f"Label: {label}"
if predicted is not None:
title += f" | Predicted: {predicted}"
plt.title(title)
plt.axis('off')
plt.show()
# ---------------------- AĞ BAŞLATMA ----------------------
def init_params():
w1 = np.random.rand(10, 784) - 0.5
b1 = np.random.rand(10, 1) - 0.5
w2 = np.random.rand(10, 10) - 0.5
b2 = np.random.rand(10, 1) - 0.5
return w1, b1, w2, b2
# ---------------------- FORWARD PROPAGATION ----------------------
def forward_prop(w1, b1, w2, b2, X):
z1 = w1 @ X + b1
a1 = relu(z1)
z2 = w2 @ a1 + b2
a2 = softmax(z2)
return z1, a1, z2, a2
# ---------------------- BACKWARD PROPAGATION ----------------------
def backward_prop(z1, a1, z2, a2, Y, X, w2):
y_true = one_hot(Y)
dz2 = a2 - y_true
dw2 = dz2 @ a1.T
db2 = dz2
dz1 = (w2.T @ dz2) * relu_derivative(z1)
dw1 = dz1 @ X.T
db1 = dz1
return dw1, db1, dw2, db2
# ---------------------- EĞİTİM FONKSİYONU ----------------------
def train(data, epochs, learning_rate):
w1, b1, w2, b2 = init_params()
for epoch in range(epochs):
np.random.shuffle(data)
total_loss = 0
correct = 0
for i in range(len(data)):
label = int(data[i, 0] * 255)
X = data[i, 1:].reshape(784, 1)
z1, a1, z2, a2 = forward_prop(w1, b1, w2, b2, X)
loss = -np.sum(one_hot(label) * np.log(a2 + 1e-8))
total_loss += loss
if np.argmax(a2) == label:
correct += 1
dw1, db1, dw2, db2 = backward_prop(z1, a1, z2, a2, label, X, w2)
w1 -= learning_rate * dw1
b1 -= learning_rate * db1
w2 -= learning_rate * dw2
b2 -= learning_rate * db2
acc = correct / len(data)
print(f"Epoch {epoch+1}/{epochs} - Loss: {total_loss:.4f} - Accuracy: {acc:.4f}")
return w1, b1, w2, b2
# ---------------------- ANA DÖNGÜ ----------------------
# Eğitim
w1, b1, w2, b2 = train(traindata[:4000], epochs=10, learning_rate=0.01)
# Etkileşimli tahmin ve gösterim
while True:
sample = random_value(testdata)
label = int(sample[0] * 255)
X = sample[1:].reshape(784, 1)
_, _, _, a2 = forward_prop(w1, b1, w2, b2, X)
prediction = np.argmax(a2)
show_image(sample, predicted=prediction)
print(f"Gerçek Etiket: {label} | Tahmin: {prediction}")
x = input("Devam etmek için Enter, çıkmak için 'q': ")
if x.lower() == "q":
break
Sinir Ağı Tipleri ve kullanım alanları
Sinir ağları, farklı yapı ve mimarilerle farklı amaçlar için tasarlanabilirler. İhtiyaca göre ağın tipi değişir.Layer sayısı ve tipi önemlidir.Layer sayısı artıkça model karmaşıklarşır ve daha derin konularda çıkarımlarda bulunmaya başlar.Günümüzde model parametleri insanların anlamayacagı seviyede karmaşıklık seviyelerine ulaşmıştır.Ayrıca long time short memory gibi kavramların hayatımıza girmesi ile modeller hafıza yetenegine sahip olabilmektedir.Bu tip konulara girmeden önce temel network tiplerine bakalım
Feedforward neurol network (Multi-layer perceptron)
Bir tane hidden layer olan en temel yapay sinir agı biçimidir.Temel sınıflandırma ve regresyon problemlerinde yaygın olarak kullanılır.butun neuronlar önceki layer butun neuronlarına baglıdır bu da mlp full connected layer yapar.
Recurrent Neural Network
Zaman serisi verilerini ve ardışık bilgileri işlemek için tasarlanmıştır.Doğal dil işleme, konuşma tanıma, hava tahmini gibi alanlarda kullanılır.Bellek özeleigi sayesinde daha derin konularda kullanılabilir.
Convolutional Neural Network (CNN)
Konvolüsyonel Sinir Ağları (CNN), özellikle görüntü işleme ve bilgisayarla görme alanlarında kullanılan bir yapay sinir ağı türüdür. Girdi verisini bir dizi konvolüsyonel filtre ile işler ve öznitelik çıkarımı yapar. Görüntü sınıflandırma, obje tespiti ve segmentasyon gibi görevlerde yaygın olarak kullanılır. Katman yapısı genellikle konvolüsyonel katmanlar, havuzlama (pooling) katmanları ve tam bağlantılı katmanlardan oluşur.
Generative Adversarial Networks
Generative Adversarial Networks, veri üretmek için kullanılan bir yapay sinir ağı modelidir. İki bileşenden oluşur: Üretici ağ (Generator) ve Ayrımcı ağ (Discriminator). Üretici ağ, gerçekçi sahte veriler üretmeye çalışırken; ayrımcı ağ, üretilen veriyi gerçek veriden ayırt etmeye çalışır. Görüntü oluşturma, veri artırma ve stil transferi gibi uygulamalarda yaygın olarak kullanılır.
Deep Neural Network
Derin sinir ağları, birden fazla gizli katmana sahip yapılar olarak tanımlanır. Bu ağlar, yüksek veri hacimleri ve karmaşık problemlerin çözümü için uygundur. Görüntü işleme, doğal dil işleme ve konuşma tanıma gibi alanlarda derin öğrenme tekniklerinin temelini oluşturur.
Autoencoders
Autoencoderlar, veriyi sıkıştırmak ve yeniden oluşturmak için kullanılan yapay sinir ağı modelleridir. Girdi verisini daha düşük boyutlu bir gösterime indirger ve ardından bu gösterimi tekrar orijinal boyuta dönüştürmeye çalışır. Özellikle öznitelik çıkarımı, veri gürültüsünü azaltma ve boyut indirgeme gibi uygulamalarda kullanılır.